How we’ve saved 98% in cloud costs by writing our own database

What is the first rule of programming? Maybe something like “do not repeat yourself” or “if it works, don’t touch it”? Or, how about “do not write your own database!”… That’s a good one.
Databases are a nightmare to write, from Atomicity, Consistency, Isolation, and Durability (ACID) requirements to sharding to fault recovery to administration - everything is hard beyond belief.
Fortunately, there are amazing databases out there that have been polished over decades and don’t cost a cent. So why on earth would we be foolish enough to write one from scratch?
Well, here’s the thing…
We are running a cloud platform that tracks tens of thousands of people and vehicles simultaneously. Every location update is stored and can be retrieved via a history API.
The amount of simultaneously connected vehicles and the frequency of their location updates varies widely over time, but having around 13.000 simultaneous connections, each sending around one update a second, is fairly normal.
Our customers use this data in very different ways. Some use cases are very coarse, e.g. when a car rental company wants to show an outline of the route a customer took that day. This sort of requirement could be handled with 30-100 location points for a one hour trip and would allow us to heavily aggregate and compress the location data before storing it.
But there are many other use cases where that’s not an option. Delivery companies that want to be able to replay the exact seconds leading up to an accident. Mines with very precise, on-site location trackers that want to generate reports of which worker stepped into which restricted zone - by as little as half a meter.
So - given that we don’t know upfront what level of granularity each customer will need, we store every single location update. At 13k vehicles that’s 3.5 billion updates per month - and that will only grow from here. So far, we’ve been using AWS Aurora with the PostGIS extension for geospatial data storage. But Aurora costs us upwards of $10k a month already, just for the database alone - and that will only become more expensive in the future.
But it’s not just about Aurora pricing. While Aurora holds up quite well under load, many of our customers are using our on-premise version. And there, they have to run their own database clusters which are easily overwhelmed by this volume of updates.
Why aren’t we just using a database, purpose built for geospatial data?
Unfortunately, there is no such thing. (If there is and we somehow overlooked it in our research, please let me know). Many databases, from Mongo and H2 to Redis support spatial data types like points and areas. And there are “Spatial Databases” - but they are exclusively extensions that sit on top of existing DBs. PostGIS, built on top of PostgreSQL is probably the most famous one, but there are others like Geomesa that offer great geospatial querying capabilities on top of other storage engines.
Unfortunately, that’s not what we need.
Here’s what our requirement profile looks like:
- Extremely high write performance
We want to be able to handle up to 30k location updates per second per node. They can be buffered before writing, leading to a much lower number of IOPS. - Unlimited parallelism
Multiple nodes need to be able to write data simultaneously with no upper limit - Small size on disk
Given the volume of data, we need to make sure that it takes as little space on disk as possible
This means, we’ll have to accept some trade-offs. Here’s what we are ok with:
-
Moderate performance for reads from disk
Our server is built around an in-memory architecture. Queries and filters for real time streams run against data in memory and, as a result, are very fast.
Reads from disk only happen when a new server comes online, when a client uses the history API or (soon) when an app user rewinds time on our digital twin interface. These disk reads need to be fast enough for a good user experience, but they are comparatively infrequent and low volume. -
Low consistency guarantees
We are ok with losing some data. We buffer about one second worth of updates before we write to disk. In the rare instances where a server goes down and another takes over, we are ok with losing that one second of location updates in the current buffer.
What sort of data do we need to store?
The main type of entity that we need to persist is an “object” - basically any vehicle, person, sensor or machine. Objects have an id label, location and arbitrary key/value data, e.g. for fuel levels or current rider id. Locations consist of longitude, latitude accuracy, speed, heading, altitude and altitude accuracy - though each update can only change a subset of these fields.
In addition we also need to store areas, tasks (something an “object” has to do), and instructions (tiny bits of spatial logic the hivekit server executes based on the incoming data).
What we’ve built
We’ve created a purpose built, in process storage engine that’s part of the same executable as our core server. It writes a minimal, delta based binary format. A single entry looks like this:
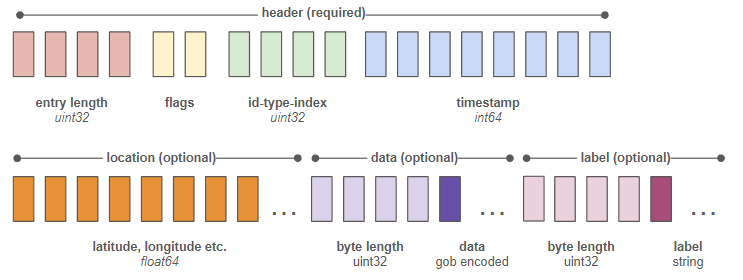
Each block represents a byte. The two bytes labeled “flags” are a list of yes/no switches that specify “has latitude”, “has longitude”, “has data” etc. - telling our parser what to look for in the remaining bytes of the entry.
We store the full state of an object every 200 writes. Between these, we only store deltas. That means that a single location update, complete with time and id, latitude and longitude only takes 34 bytes. This means, we can cram about 30 million location updates into a Gigabyte of disk space.
We also maintain a separate index file that translates the static string id of each entry and its type (object, area etc.) into a unique, 4 byte identifier. Since we know that this fixed size identifier is always byte index 6-9 of each entry, retrieving the history for a specific object is extremely fast.
The result: A 98% reduction in cloud cost and faster everything
This storage engine is part of our server binary, so the cost for running it hasn’t changed. What has changed though, is that we’ve replaced our $10k/month Aurora instances with a $200/month Elastic Block Storage (EBS) volume. We are using Provisioned IOPS SSD (io2) with 3000 IOPS and are batching updates to one write per second per node and realm.
EBS has automated backups and recovery built in and high uptime guarantees, so we don’t feel that we’ve missed out on any of the reliability guarantees that Aurora offered. We currently produce about 100GB of data per month. But, since customers rarely query entries older than 10 days, we’ve started moving everything above 30GB to AWS Glacier, thus further reducing our EBS costs.
But it’s not just cost. Writing to a local EBS via the file system is a lot quicker and has lower overhead than writing to Aurora. Queries have gotten a lot faster too. It’s hard to quantify since the queries aren’t exactly analogous, but for instance recreating a particular point in time in a realm’s history went from around two seconds to about 13ms.
Of course, that’s an unfair comparison, after all, Postgres is a general purpose database with an expressive query language and what we’ve built is just a cursor streaming a binary file feed with a very limited set of functionality - but then again, it’s the exact functionality we need and we didn’t lose any features.
You can learn more about Hivekit’s API and features at https://hivekit.io/developers/